



















- 庫存 > 10
 放入購物車
放入購物車 直接結帳
直接結帳 放入下次購買清單
放入下次購買清單-




深度學習的商戰必修課:人工智慧實用案例解析,看35家走在時代尖端的日本企業如何翻轉思考活用AI
- 作者:日經xTREND(日経クロストレンド)
- 出版社:臉譜
- 出版日期:2020-01-30
- 定價:420元
- 優惠價:75折 315元
-
書虫VIP價:315元,贈紅利15點
活動贈點另計
可免費兌換好書 - 書虫VIP紅利價:299元
- (更多VIP好康)
-
購買電子書,由此去!
本書適用活動







分類排行
-
這次不遲到!有感筆電超激推100款ROBLOX絕讚遊戲

-
一起歡樂玩ROBLOX:快速上手、TOP遊戲、密技爆料、遊戲設計滿載!

-
Roblox官方授權完全攻略:開發遊戲聖典24Hours就能學會

-
邊做邊玩邊學速成攻略!Roblox遊戲設計大全

-
一本讀通英文文法.詞性:圖解英文詞性與慣用法

-
一本讀通高中英文:圖解基礎英文文法

-
Excel 公式+函數職場專用超級辭典【暢銷第二版】:新人、老鳥到大師級都需要的速查指引

-
大家一起學習日文吧!王可樂日語高級直達車:詳盡文法、大量練習題、豐富附錄、視聽影音隨時看

-
大家一起學習日文吧!王可樂日語中高級直達車:詳盡文法、大量練習題、豐富附錄、視聽影音隨時看

-
鍛鍊問題解決力!演算法與資料結構應用全圖解

內容簡介
———從研究邁向實用,見證35家日本先進企業如何成功應用「深度學習」————
日本AI書籍第一人、東京大學松尾豐教授解說深度學習的發展預測
LINE、可口可樂、本田、樂天、NHK、So-net、佳能醫療系統……
第一手訪談先驅者的前瞻思考,掌握智慧化新技術的無限商機
★深入導讀深度學習的發展:影像辨識、多模式辨識、機器人學、互動、符號接地、知識擷取!
★為運用AI技術的企業經常遇到的疑問提出解答,次世代新興事業、企業創造價值必讀教本!
★直擊AI計畫推動者的挑戰與艱辛,收錄大量照片和圖表,身歷其境感受快速擴展的深度學習應用的今日與未來!
【各界讚譽推薦】
何英圻 ∣ 91APP董事長
呂曜志 ∣ 台北海洋科技大學副校長
陳良基 ∣ 科技部部長
郭奕伶 ∣ 商周集團執行長
張嘉惠 ∣ 中華民國人工智慧學會理事長
陶韻智 ∣ 德豐管顧公司合夥人、LINE台灣區前總經理
程世嘉 ∣ iKala共同創辦人暨執行長
詹宏志 ∣ PChome Online網路家庭董事長
楊立偉 ∣ 國立臺灣大學工商管理學系教授
盧希鵬 ∣ 國立臺灣科技大學資訊管理系專任特聘教授
謝宗震 ∣ 智庫驅動公司知識長
魏澤人 ∣ 國立交通大學AI學院副教授
蘇書平 ∣ 為你而讀執行長
■ 以AI為眼、為腦,實現五感預測,邁向高階思考溝通!
扮演第三次人工智慧熱潮領頭羊角色的深度學習,正以銳不可擋之姿進化。做為人工智慧時代的通用技術,「深度學習」蘊藏著能夠改變一切產業中所有業務、創造新事業的潛力。本書不是探討深度學習技術的深奧知識,而是希望藉由多樣化的實際案例,找出靈活運用的「模式」。
豬排丼盛裝方式的判定、計算游動中的鮪魚數量、辨別送洗的衣類、文章的校閱、判斷河川護岸的損壞、輸電線的異常檢測、探測路面下的空洞、預測計程車的乘客人數、預估電視廣告的效果、便當的裝飾、黑白影像的上色技術、繪製虛擬偶像的圖像、跟專業人士一樣的主播、模仿卡通人物語音的智慧音箱……分門別類介紹深度學習的驚人運用法。
本書由專精市場行銷和創新的日本數位媒體「日經xTREND」編纂,長期關注企業最先進數位策略和新事業規畫的專業記者撰文。此外,人工智慧專家將解答企業在商業應用上經常面臨的問題,包括值得挑戰的領域、需要的人才、費用估算、成功活用的關鍵要素等。
或許不是每個人都會開發AI、都需要思考AI運用,但人人都是AI消費者、獲益者、享受者,也是受AI影響者。透過本書,見證人工智慧如何深入我們的生活,改變世界!
■ 從大企業到中小企業,從金融保險、零售流通、醫療保健、機械交通到文創媒體
系統化歸納深度學習活用案例,找出高效運用的最佳模式!
01 以影像辨識實現自動結帳的無人櫃臺,與人的合作比辨識準確率更重要
02 用約七百台自行研發的人工智慧攝影機「實際A/B測試」
03 日版「Amazon Go」的實驗,以人工智慧實現預防竊盜技術
04 分析社群網站的圖像貼文,掌握消費情境
05 大幅縮短製作估價單的時間,增加保險提案的「打數」
06 以人工智慧將租賃物件照片自動分類,每個月減少三千小時的作業
07 翻譯手語的小型機器人,設置於銀行櫃臺等窗口協助對話
08 藉由智慧型手機圖像分析,計算食物熱量和判定體態
09 使用亞馬遜的影像辨識API,將環境改善人工智慧服務事業化
10 運用人工智慧掌握鮪魚養殖數量,每年減少超過兩百五十小時的作業
11 福岡的乾洗店以五十萬日圓打造「人工智慧無人櫃臺」的原因
12 校對人工智慧效果驚人,檢測率超過人類,只需幾秒即完成
13 以人工智慧檢測河川護岸受損狀況,驗證公共基礎工程更有效的檢驗法
14 運用於檢測輸電線異常,希望提升五倍生產力
15 本田旗下汽車零件製造商,試作不良品自動偵測系統
16 藉由一般人工智慧與優秀人工智慧結合,實現自動化檢查半導體晶圓外觀
17 追蹤路面下空洞的變化,偵測塌陷危險性高的地點
18 使用滿載保全警備專業技能的人工智慧來防止竊盜
19 研發車用保護駕駛感測器,判定認知、判斷和操作狀況
20 使用智慧型手機拍照,就能自動輸入上架商品類別和名稱
21 菜鳥駕駛勝過經驗豐富的中堅員工!人工智慧計程車的威力
22 以人工智慧預測人的移動並加以視覺化,布局近未來的交通系統
23 學習約一萬支電視廣告影片,在播放前精準預測效果
24 橫幅廣告點擊率高低的預測準確率,專家百分之五十三對人工智慧百分之七十
25 日本國內醫療第一線首次實際使用運用深度學習的儀器
26 以深度學習來讓機器人取出散裝零件
27 老字號企業與新創公司合作,挑戰解開「夾取義大利麵」的難題
28 實現油壓挖土機自動挖掘作業,輸入資料和人員作業一樣只靠影像
29 從屬性識別到軌道生成的六項功能都適用人工智慧,朝自動駕駛邁進
30 以人工智慧提升黑白影像彩色化的效率,五天的作業一日完成
31 實現自動生成「偶像臉」,目標是創意人工智慧實用化
32 超越亞馬遜Alexa的「人工智慧播報員」能流暢說話的原因
33 Clova的「個性化」策略,以約四小時的語音資料來模擬說話方式
34 實現電視劇字幕自動翻譯作業超越專業人員的品質
35 讓機器人能理解情感,實現高階溝通
■ 對本書的讚譽
何英圻 ∣ 91APP董事長
對零售對品牌來說,沒有「對的資料」,就沒有AI。唯有正確的資料,機器才能理解、學習。但是零售數據龐雜,線上線下數據異質性高,我看到許多品牌,光要打通線上線下資料,再進而資料可以正確一致,就面臨非常巨大挑戰。縱使有再強的AI算力、演算法,沒有對的資料,是做不到虛實融合(OMO),遑論AI帶來的龐大效益。如本書所提,AI並非萬能,要站在實際應用場景來設計,才會做出讓企業致勝的武器。現在距離不需要人的時代還很遙遠,要使用AI驅動企業競爭力,就要回到如何理解AI善用AI,這才是未來十年的重點,也是本書精髓。
呂曜志 ∣ 台北海洋科技大學副校長
人工智慧應用科技的目的,事實上不是要取代人,而是要取代人的某些耗費心力的勞動與時間投入,使得人類從繁雜的勞動中被解放出來,從而投入更有創造性與決策性的心智活動。因此人工智慧在企業上的應用,其實是一種分層負責與決行的概念,讓所有能夠被清楚定義(Well Defined)與數量化,且不牽涉到動態競爭賽局的決策,賦權給人工智慧來處理過程中的決策資訊,而最後由人類來審核與拍板。
除了解釋決策者給予的問題之外,人工智慧的下一步,將是從大量結構性與非結構性的資料當中,看到決策者所看不到的問題。因此人工智慧對企業管理的未來,有如數位的斷層掃描儀,一層一層診斷與凸顯企業的問題。既然是診斷企業,就要有大量的臨床成功病例,這本書提供了三十五家日本各領域先進企業應用人工智慧、精進企業經營的實際案例,值得任何有志於探討企業管理議題的讀者參考。
程世嘉 ∣ iKala共同創辦人暨執行長
數位轉型從以往的數位化、IT升級階段,正式進入以AI為核心驅動的商業轉型階段。AI技術經過多年發展,已經快速商品化,變成人人可用。現在,一位不會寫程式的行銷人員,都能輕易上手AI工具,來改善工作流程和成效。iKala 提供以AI為核心的商業轉型解決方案,在六個國家,服務超過三百五十間、橫跨超過十二種產業的企業客戶,親身參與AI在不同商業場景的落地和實踐。本書以場景分類出發,有條有理歸類不同企業使用深度學習技術改善商業流程的方式,諸多案例令人大開眼界,值得一讀。
謝宗震 ∣ 智庫驅動公司知識長
本書彙整了大量人工智慧應用案例,透過訪談先驅者的第一手材料,理解人工智慧應用是如何在既有工作流程中進行顛覆式創新。譬如怎麼樣讓豬排丼看起來更美味、如何系統性偵測路面坑洞、如何實現挖土機自動挖掘作業。
在終章更整理了實務專家在商務運用的關鍵議題,包含場景、資料、人才、外援、預算。精讀本書有助於讀者建立有效的決策,創造有價值的應用,本人誠摯推薦。
魏澤人 ∣ 國立交通大學AI學院副教授
在產業中應用深度學習技術,需要資料科學家、資料工程師、軟體工程師、使用者經驗、行銷等等不同領域的人才。要讓這麼多不同領域的專家合作和溝通,相當有挑戰。也許需要更多像書中所提的「左右開弓型」人才。本書中舉出許多AI在日本產業上的案例,很值得參考。
目錄
前言
【第一章 深度學習的發展預測】
深度學習現況╱深度學習的發展路線圖╱(1)影像辨識╱(2)多模式辨識╱(3)機器人學╱深度學習是通用技術╱提供國王般的服務╱課題是人才不足,業界不約而同開始培養人才
【第二章 [Step 1]成為人類的「眼睛」擺脫單純的作業】
case01 Signpost
將排隊結帳當作社會課題來面對╱不知道的東西就會判斷「不知道」╱未來也會成為收集商品圖像資料的事業體╱將購買日用品變成「愉快」的場所
case02 Trial Holdings
連人工智慧攝影機也貫徹自行研發精神╱掌握貨架陳列狀況和顧客對商品的接觸度╱也測試了Panasonic的人工智慧攝影機╱讓任何人都能做到資深人員的裝盤方式╱區別「香菇山」與「竹筍村」
case03 VAAK
實現不需要感測器的無人商店
case04 日本可口可樂 Coca-Cola Japan
從十萬張圖像來分析飲用情境
case05 損害保險日本興亞 Sompo Japan Nipponkoa Insurance Inc.
購車後保險提案困難的原因╱增加保險提案的「打數」
case06 大東建託 Daito Trust Construction
一個半月達到模型化╱追求業務上「容易操作」的系統
case07 NTT DATA
對RoBoHoN用手語交談,機器人就會發出日語╱可判讀五百個手語字彙╱運用姿態估測模型
case08 FiNC Technologies
可辨識一百三十五種料理╱運用龐大的資料量作為強項╱以一百個等級來評估體態的人工智慧╱服務研發與人工智慧研發的「雙刀派」
case09 AUCNET IBS
用深度學習來辨識照明設備的「安定器」型號╱制定實務上的最終目標,運用深度學習
case10 双日鮪魚養殖場鷹島 Sojitz Tuna Farm Takashima
掌握鮪魚數量至關重要╱逐格播放影片來計算鮪魚數量╱「直覺認為那是不可能辦到的」╱研發鮪魚專用計數應用程式╱如何在網路環境不佳的鷹島實施?
case11 LANDA
只要把衣物放在桌上就能自動判別╱如果可以分辨狗跟貓,應該也分得出西裝與長褲╱相較於人工智慧完成度,更重視無人櫃臺的落實程度╱努力吸收知識,盡量控制投資
【第三章 [Stpe 2]扮演「五官」角色,預測行動、偵測異常】
case12 瑞可利 Recruit Holdings
校對員工人數大幅減少╱檢測率達百分之八十二至百分之八十三
case13 八千代機械 Yachiyo Engineering
將一百五十張照片加工成一萬多筆資料╱如果進一步制訂出規則等使用環境,就會儘快普及
case14 東京電力電網公司 東京電力Power Grid
一年多達約一千四百小時監控作業╱架空輸電線診斷系統由四項功能組成╱挖掘各個事務所保存的資料來提高準確率╱應用於檢驗電塔或結構物生鏽的可能性
case15 武藏精密工業 Musashi Seimitsu Industry
幾乎能實現與人工目視檢查相近的準確率
case16 藤倉 Fujikura
正確率超過百分之九十九
case17 川崎地質 Kawasaki Geological
用過去的調查結果作為訓練資料學習╱用新的探測設備收集超過百倍資料
case18 綜合警備保障 ALSOK
藉由深度學習實現新型態的待客之道
case19 歐姆龍 OMRON
適用第二級自動駕駛的駕駛專注度感測╱以時間序列的深度學習來辨識駕駛人舉動
case20 Mercari
藉由影像辨識自動登錄分類╱準確率低仍能實現「感動上架」╱利用多模式辨識偵測違規上架╱更新模型並建立公開機制不可或缺
case21 東京無線協同組合 Tokyo Musen
人口統計×行駛狀況×氣象×設施資料╱為了提升準確率而擴充資料量╱以混合方式預測,採用接近實測值的模型
case22 順風路 JUNPUZI
運用從全國超過四十個地方政府收集到的資料╱計畫運用針對交通行動服務(MaaS)領域的資料╱以移動和氣象資訊等資料來預測需求
case23 Video Research
將十年分的一萬支廣告以每支十五張圖像來分析
case24 So-net媒體網路公司 So-net Media Networks
用三萬五千則橫幅廣告來學習
case25 佳能醫療系統 Canon Medical System
可以重建在低輻射量下同等解析度的電腦斷層攝影影像╱磁振造影影像也用深度學習來去除雜訊
國外案例
Viz.ai、IDx、Imagen Technologies 、Arterys等深度學習在美國醫療第一線陸續商品化
【第四章 [Stpe 3]彈性因應現實社會的「機器人」、「自動駕駛」時代】
case26 發那科 FANUC
通知零件更換時期,減少不必要的作業╱收集大量理想的訓練資料╱實現高準確率拾取散裝的零件╱即使無法百分之百保證也能產生價值嗎?
case27 石田 ISHIDA
仰賴人海戰術的工廠所面臨的現實╱藉由深度學習讓盛裝作業自動化╱獲選為優良人工智慧新創研究專案
case28 藤田 FUJITA
日本能以人工智慧致勝的是營建領域╱將熟練操作人員的動作數據化╱準備資料和建置系統耗時一年
case29 本田技研工業 HONDA
只靠三架攝影機的資訊來實現自動駕駛╱認知功能與行動計畫功能大幅進化╱將自動駕駛要求的功能由上到下縱向分割
國外案例
Robby Technologies、BoxBot、Nuro、Robomart等威脅機器人大國日本的矽谷環保系統
【第五章 拓展至「創作」業務的運用範圍】
case30 NHK ART
四十分鐘的彩色化費時約三個月,希望提高效率╱整體而言呈泛黃褐色,是個大問題╱從人工作業的五天到用人工智慧一天完成╱動態多的場景也能順利上色
case31 DataGrid
以深度學習來辨識偶像的特徵╱生成「擬真影像」的技術有什麼用處?
case32 Spectee
「荒木結衣」是何方神聖?╱在機器學習上加入微調讓發音更流利╱提供適用Alexa的模組拓廣運用
case33 LINE
將出現以孫子聲音發聲的智慧音箱?
case34 樂天 美國Rakuten VIKI
卓越的自動翻譯背後有高品質的訓練資料
case35 Unirobot
適才適所運用深度學習等人工智慧技術╱也分析和運用個性等性格
【第六章 理解商業運用關鍵的六大疑問】
Q1 應該積極評估運用人工智慧的商務課題是哪些?另外還有哪些具挑戰性的領域?
從業務效率化推動使用╱不以人工智慧為前提╱參考先行案例是否恰當?╱其他公司的成功不保證自家公司也會成功╱人工智慧擅長找出規則性和順序╱看來費工耗時的作業就靠人工智慧╱人工智慧能做的是自動化和模式化
Q2 應該運用雲端應用程式介面提供的人工智慧是哪些情況?什麼情況又該研發自有模型?
先在雲端上評估╱盡量輕鬆作業╱使用應用程式介面有哪些課題?╱面對的問題能否靠應用程式介面解決?╱研發適用於商業課題的人工智慧
Q3 人工智慧運用在哪類資料比較容易?哪類資料比較困難?
有無後設資料將影響作業工程╱適合運用的資料的六項條件╱思考收集所需資料的機制
Q4 在推動人工智慧運用上,公司裡需要有哪些人才?哪些人才應靠外部支援?
需要的人才有四種╱思考從準確率到商業上的意義╱可以運用人工智慧的人才應該了解的技術╱有完整人工智慧教育計畫的Future
Q5 運用人工智慧的費用應該如何估算?
首先判斷是否該在前期概念驗證下開發╱以機器學習應用系統的每個生命週期來付費╱分割任務依序判斷是否能實現╱以導入的四個項目和運用的兩個項目來彙整費用╱別吝於在標註上投資╱同樣的專案也會有超過十倍的價差
Q6 成功運用人工智慧的關鍵是什麼?
經營的想像力╱業務影響和費用估算╱以多產多死為前提,持續挑戰
結語
內文試閱
case10 双日鮪魚養殖場鷹島 Sojitz Tuna Farm Takashima
運用人工智慧掌握鮪魚養殖數量,每年減少超過兩百五十小時的作業
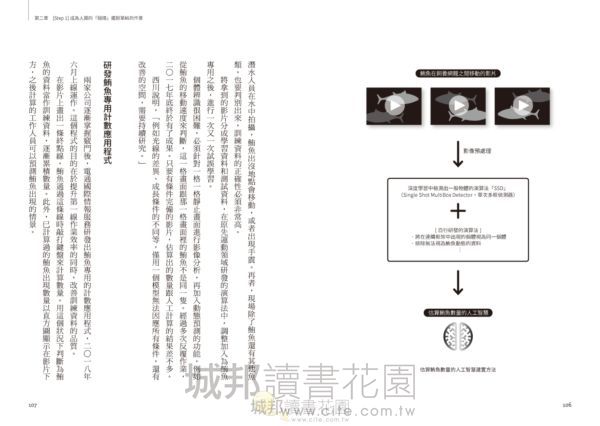
鮪魚養殖業的重點之一是正確掌握飼養網籠裡的鮪魚數量,這樣才能計算最理想的餌食需求量。魚餌的開銷占了一半以上的成本。双日與電通國際情報服務(ISID)合作,利用深度學習來掌握鮪魚的數量。據說一開始相關人士認為是「不可能」的挑戰,但經過實測後效果頗佳,已經朝正式研發邁出一大步。
綜合商社双日為了穩定供應日漸減少的鮪魚,二○○八年於長崎縣松浦市鷹島以全額出資的方式成立了子公司双日鮪魚養殖場鷹島,展開鮪魚養殖事業。二○一六年十二月,在和歌山縣串本町取得漁場,該公司成立十年來事業持續擴大。
◎掌握鮪魚數量至關重要
鮪魚養殖業花三年時間才能出貨,超過一半的成本花在餌食上。因此,如何估算出最理想的餌食量成了首要之務。要推估理想的餌食量,必須正確掌握飼養網籠裡究竟有多少鮪魚。餌食給得太多,造成資源浪費;反之若給太少,又導致鮪魚品質下滑。
双日食料暨農業業務本部食料暨水產部水產事業課專任課長石田伸介說明,「水產業有很多地方還是個人經驗的傳授,業界發展科技資訊化的腳步較慢。假設餌食量差一成,幾年下來數量很可觀。不過,目前仍然普遍倚賴漁夫的經驗法則來訂定餌食量。如果這個部分能夠數據化,沒經驗的年輕人也能輕鬆進入這一行。對於勞動力逐漸高齡化的水產業來說,推動資訊科技化具備各種不同層面的意義。」
然而,計算鮪魚的數量可沒那麼容易。飼養網籠的直徑有四十公尺,最深的地方達二十公尺,相當巨大。鷹島大約有三十處飼養網籠,以不同飼養年分來管理。每一處飼養網籠大約有一千五百尾幼魚,但隨著時間過去,網籠內的情況大幅改變。有些鮪魚死掉,有些其他種類的魚從漁網縫隙鑽進來。過去只能靠漁夫從鮪魚吃餌的情況來判斷大致的數量。
◎逐格播放影片來計算鮪魚數量
將幼魚放進飼養網籠後,得等到把鮪魚移到另一處飼養網籠時才有機會計算數量。拉開網籠之間的網子,然後由潛水員深入海中拍攝鮪魚通過時的影片。把這幾十分鐘長的影片逐格播放,由工作人員一尾一尾計算,長的時候大概花上五小時觀看。五名工作人員各自進行之後,對照結果推算出一個正確的數量。這是過去採用的方法。
石田說明,「這種做法非常耗費時間和人力成本。但鮪魚數量又是重要的關鍵,不可能不計算。這項作業該怎麼提升效率,始終是一大課題。」
近三十處飼養網籠,到可出貨的三年多期間,鮪魚需要在網籠之間移動一、兩次,亦即一年有十次至二十次計數作業。五名工作人員需各花費五小時在這項作業上,總計每年耗掉兩百五十小時至五百小時。如果能夠自動化計數,將大幅減少作業時間。此外,能讓年輕人的就業環境變得更好,進一步期待改善雇用情況。
由於這樣的需求,讓相關人員想到是否能運用深度學習來估算鮪魚的數量。於是二○一七年初,該公司與電通國際情報服務展開合作。為了因應二○二○年的奧運和殘障奧運,電通國際情報服務其實原已進行運動中人類動態可視化的研究,所以想到是否能將這項技術運用於計算鮪魚數量。
◎「直覺認為那是不可能辦到的」
電通國際情報服務通訊IT事業部企畫總監西川敦坦言,「其實一開始看到影片中鮪魚移動的速度這麼快,直覺認為那是不可能辦到的。」
實際上,研發過程極度困難。首先,魚影的判斷非常不容易。拿到的影片受到天候、潮流等各項條件影響,而且有很多浮游生物和光線等容易誤判為鮪魚的物體資訊。此外,這些影片是由潛水人員在水中拍攝,鮪魚出沒地點會移動,或者出現手震。再者,現場除了鮪魚還有其他魚類,也要判別出來,訓練資料的正確性必須非常高。
將拿到的影片分成學習資料和測試資料,在原先運動領域研發的演算法中,調整加入為鮪魚專用之後,進行一次又一次試誤學習。
個體辨識很困難,必須針對一格一格靜止畫面進行影像分析,再加入動態預測的功能,例如從鮪魚的移動速度來判斷,這一格畫面跟那一格畫面裡的鮪魚不是同一隻。經過多次反覆作業,二○一七年底終於有了成果。只要有條件完備的影片,估算出的數量跟人工計算的結果差不多。
西川說明,「例如光線的差異、成長條件的不同等,僅用一個模型無法因應所有條件,還有改善的空間,需要持續研究。」
◎研發鮪魚專用計數應用程式
兩家公司逐漸掌握竅門後,電通國際情報服務研發出鮪魚專用的計數應用程式,二○一八年六月上線運作。這個程式的目的在於提升第一線作業效率的同時,改善訓練資料的品質。
在影片上畫出一條終點線,鮪魚通過這條線時敲打鍵盤來計算數量。用這個狀況下判斷為鮪魚的資料當作訓練資料,逐漸累積數量。此外,已計算過的鮪魚出現數量以直方圖顯示在影片下方,之後計算的工作人員可以預測鮪魚出現的情景。
這項做法讓作業時間大幅縮短,也能和其他工作人員的估測數據做比較,進一步改善第一線的作業狀況。此外,有別於過去以整段影片計算尾數的數據,現在是以一格畫面有多少尾來計算,訓練資料的品質更為提升。
今後的課題是影片標準化。為了達成目標,仍持續不斷進行試誤學習,使用各種不同的攝影方法,以及影像處理的技術。進行深度學習之前,目前還在摸索藉由資料預處理,可以將準確率提高到什麼程度。
◎如何在網路環境不佳的鷹島實施?
目前還在評估提供實際服務的方式。由於鷹島當地的網路環境並不理想,營運上該怎麼交換資料,必須進一步評估伺服器建置在雲端或在現場設置功能更強大的設備。
計數應用程式的下一步,是在深度學習辨識的魚影上加框,讓計數變得更容易,最終目標希望能區分鮪魚與其他魚種,達到完全自動化。
西川談到今後的展望,「就像汽車的自動駕駛一樣,不可能一蹴可幾。我們將配合運動界的技術研發,目標是在二○二○年實現這項技術。」
石田表示,「正因為有我們這樣的規模,才能收集到夠多的資料。想到或許能幫助其他養殖業者解決課題,我們希望盡量做出貢獻。藉由收集更多資料,讓影像更加鮮明,就能提升準確率,最後達到超越人工作業的效果。」他在言談中充滿期待。
case20 Mercari
使用智慧型手機拍照,就能自動輸入上架商品類別和名稱
日本國內每個月超過一千萬人使用跳蚤市場應用程式「Mercari」,一年(二○一八年度)交易額高達三千四百六十八億日圓。深度學習在提升使用者體驗和實現安心交易上,發揮了很大功效。
Mercari的深度學習影像辨識運用有兩大方向。一是藉由提高服務的便利性,實現更好的使用者體驗;另外則是因應現金或演唱會票券等違反法律或規定的上架商品。
二○一八年七月,累積的上架商品數量高達十億,Mercari保存包括這些照片、商品簡介文字等豐富的資料,對於運用深度學習的環境來說,相對得天獨厚。然而,通往目標的道路並非一帆風順。之所以能克服障礙,憑藉的正是Mercari的「Go Bold」(放膽去做)精神。
◎藉由影像辨識自動登錄分類
二○一七年十月,Mercari推出影像辨識功能。用戶只要將想上架的商品用應用程式拍照,就會自動輸入商品名稱和類別。模型以深度學習過去的上架商品資料和影像來推論,顯示出商品名稱等選項。然而,相較於用戶上架商品數量,實際上自動輸入的情況不到一半。
原因是即使使用深度學習,仍然很難區分。用戶上架的商品影像受到拍攝的相機、光源、拍攝方向、背景等環境影響而異。例如,同樣是服裝類,放在地板上拍攝與穿在人體上拍攝,很難判斷是同一類商品。
深度學習的影像辨識經常宣稱可以「超越人類」。事實上,在全球性的視覺辨識競賽ILSVRC中,在有限的資料集裡的確能達到近百分之百的準確率。然而,如果像Mercari這樣實際運用在服務上,準確率會明顯大幅下滑。
除了上述的影像多樣性問題,太陽眼鏡和後背包等男女共用的品項,究竟是女性服飾配件還是男性服飾配件,基本上無法區別。
因為這些狀況,關於影像辨識服務功能上線這件事,工程師最初顯得裹足不前。
◎準確率低仍能實現「感動上架」
「研發了功能之後,有近半年的時間都在煩惱,(在低準確率的情況下)辨識類別和品牌究竟有多大意義。最後由服務部門高層做決策,認為只要能激勵人去行動、讓用戶感動,即使準確率低,也應該推出這項功能。」(軟體工程師山口拓真)
縱使準確率低,仍執意搭載以影像辨識自動輸入商品名稱和類別的功能,還有一個明確的原因。因為判定的準確率低而不自動輸入,藉此提高這項功能對用戶來說的準確率。換言之,實際加入這項功能,即使誤判也不會令使用者失望;另一方面,若能正確判定且自動輸入商品資訊,還能提供驚喜的新體驗。
Mercari倡導的公司精神是「Go Bold」,技術第一線同樣秉持這種作風。「不僅是機器學習,包括其他技術新事物也相對積極採納。當然,要先明確了解影響的範圍和風險。」(山口)公司內部將這種藉由影像辨識來自動輸入的功能稱為「感動上架」,目標是讓用戶認為僅是在Mercari上架商品這件事,就是很愉快的體驗。
根據這項方針,進一步擴充影像辨識技術,支援用戶上架商品的功能。例如,現在只要拍攝書籍封面,就能自動輸入書名。過去可以做到拍攝條碼後自動輸入,現在又成功減少一個步驟。
此外,影像辨識使用的是Google研發的深度學習影像辨識模型「Inception-v3」,新增了Mercari的上架商品影像學習後研發而成。
學習所使用的影像有時多達一千萬筆左右。使用的影像資料筆數因研發的各個模型而異,決策以推論準確率所需的學習時間、所需的圖形處理器伺服器費用等的均衡而定。每次學習要花上幾天時間,如果準確率只有些微提升,控制資料筆數,以便一天之內完成學習。在意識到實際服務使用的情況下,決定資料大小。
◎利用多模式辨識偵測違規上架
Mercari另一項運用影像辨識技術的部分,是因應違規上架。Mercari用戶可以檢舉通報違規上架的商品,但系統也會自動偵測出違規商品,在其他使用者看到之前進行相關處理。一天上架的商品數量高達數十萬至數百萬件,不可能全部靠人工目視來確認。因此,少不了藉由電腦等機器過濾。如果能篩選幾千件乃至幾萬件,之後就能由人工作業來判定。
從營運者的角度來說,希望只要可能違規的商品都能偵測出來,因為有這樣的動機,在技術層面上不斷挑戰。其中一個例子是多模式機器學習。偵測出違規上架的商品時,不僅影像,包括產品名稱、簡介文字、價格等各種類型的資料都會歸納進行深度學習,以便提升辨識準確率。
多模式辨識是目前廣受矚目的技術領域。「『多模式』這個詞經常聽到,實際做起來卻頻頻碰壁。而且幾乎找不到這方面的論文,也不清楚該怎麼改善。因此,根本已經不是單純的服務研發,而是用接近基礎研究的水準在鑽研。」(山口)
由於違規上架商品對社會造成重大影響,Mercari非常重視,並指出判定的模型「運作的資料量非常大」(山口)。此外,實際運作的模型一旦增加,從工程的角度來看,會出現管理問題。為了提升偵測違規的準確率,必須定期更新訓練資料讓系統再次學習,而且演算法本身必須不斷改善置換。而當規則改變,出現新型態的違規上架,必須配合安裝新的模型。
◎更新模型並建立公開機制不可或缺
「有時一名工程師必須管理超過十個模型。但這麼一來得花工夫維護管理,無法處理其他新事物。」(AI小組總工程師木村俊也)
如果沒有事先想好模型的生命週期,每次更新或新增模型時出現問題,未來很可能一直留下舊模型,成為產品研發的瓶頸。因此,Mercari針對深度學習、影像辨識,研發和使用的相關基礎建置持續進步。包括為了建立更安全的模型更新和上線機制,而且避免模型之間起衝突,聘用具備機器學習知識的基礎設備工程師。藉此降低將機器學習納入服務的門檻,並提升工程師的企圖心。最終目標希望能形成正向循環,讓產品提升更具吸引力。
case31 DataGrid
實現自動生成「偶像臉」,目標是創意人工智慧實用化
位於京都的新創公司DataGrid,持續研發將創意人的工作交給人工智慧的「創意人工智慧」。該公司提出未來全新的人工智慧運用方式,研發出能「生成」偶像臉孔的人工智慧,作為一項「創意人工智慧」。
提到近年來女性偶像的長相,都是從一大群唱唱跳跳團體之類的印象,浮現「大概是長這樣吧」。於是,藉由深度學習來建立無數種所謂的「偶像臉」。來自京都大學的新創企業DataGrid(京都市左京區)研發的「偶像自動生成AI」,正提供這類功能。該公司以高解析度、高品質自動生成虛擬的偶像臉孔,在官網上生成多個臉孔版本,並以影片來介紹連續變化的模樣。每一張變化的臉孔看起來確實都具有偶像的五官,但每一張臉各不相同。而這些都不是實際存在的「某個人」,令人感到不可思議。
DataGrid社長岡田侑貴說明該公司的目標。
「這是二○一七年在京都大學新創中心(Kyoto University Venture Incubation Center, KUViC)成立的公司,目標是研究開發生成繪畫、設計、音樂等有價值的創作內容的創意人工智慧。一直以來,大眾普遍認為設計師、創意人這類繪畫和文案撰寫的工作,是人類工作中不會被電腦取代的最後堡壘。然而,人工智慧技術日新月異,終究還是能做出可以創作的人工智慧。」其中一項實例是偶像生成AI。
岡田繼續說明,「講到以往的人工智慧,幾乎都用來辨識、預測,很少看到創作的人工智慧。DataGrid希望藉由讓人工智慧做創意人的工作,刺激創意人的想像力,打造一個人類與人工智慧共同創作的社會。公司裡的十一名員工全都具備機器學習的專業背景,在學術上也與大學展開共同研究。另外,商業面上用創意人工智慧的成果,建立起能夠授權企業的商業模式。」
◎以深度學習來辨識偶像的特徵
二○一八年六月,該公司宣布研發創意人工智慧的應用軟體「偶像自動生成AI」。這項作業的概要,是讓運用深度學習的人工智慧以幾萬張偶像大頭照來學習,使人工智慧辨識出偶像的特徵。藉由學習了偶像臉孔特徵的人工智慧,來生成虛擬的偶像臉孔。因為有無限多變化,可以創造出擁有「偶像臉孔特徵」的人臉。
在具體的手法上,使用的是「生成對抗網路」(generative adversarial network, GAN)。生成對抗網路是一種非監督式學習模型,從不給予正確答案的學習資料中,推導出結構和規則,並「生成」影像等成果。其中一個網路是試圖接近從給予的學習資料所獲得的資訊,另一個是判別真偽的網路,藉由兩者在互相對抗之下各自提高準確率,提高要求的影像等生成物的品質,因此以「對抗」為名。
岡田建立使用生成對抗網路的人工智慧模型,成功將偶像臉孔特徵做出頸部以上的高解析度(1024×1024)影像,但研發過程中面臨意想不到的狀況。「一開始使用偶像臉孔的影像來學習時,雖說看得出是臉部,但生成的大多是輪廓不完整的怪臉孔。其中一個原因是起初的資料量比較少,大概只有五千筆。另一方面,偶像的大頭照形形色色,有些影像中配戴了髮飾,或者比出勝利手勢,還有臉轉向側面的,因此有時頭髮上出現莫名其妙的圖案。最後增加了幾萬筆學習資料,在資料上有絕對的優勢,不過我深深體會到針對資料進行預處理,修正為適合學習的型態,這一點非常重要。」(岡田)
有了資料的預處理,加上自由度高的學習模型最佳化,並且有後處理(posttreatment)的機制,評估生成的影像,只留下好的顯示為成果。費盡心思,終於完成了偶像自動生成AI。
經過一番努力研發出的偶像自動生成AI,現階段還沒有明確的用途。岡田說明,不只是目前的「臉孔」,希望能用人工智慧來生成動態的虛擬偶像「全身」。這麼一來,在很多情境下都能以虛擬偶像來替代真人上場。「出現在電視廣告中的人物或電商服飾模特兒,未必一定得是真人。如果能用人工智慧模特兒來替代真人藝人,想降低成本的廣告或電商網站就能使用虛擬人物。」(岡田)即使因為成本而無法採用真人,生成高解析度且幾近真實的人物影像,同樣帶來新的創意。
◎生成「擬真影像」的技術有什麼用處?
使用生成對抗網路生成新資料的人工智慧,可說是DataGrid的核心技術。換言之,DataGrid的業務不只是偶像自動生成。
另一個接近偶像自動生成的領域是「內容(contents)自動生成」。運用生成對抗網路,以動畫人物或電玩遊戲中使用的地下迷宮(dungeon)作為學習資料建立模型,生成前所未有的「具備動畫人物特徵的影像」或「具備電玩遊戲地下迷宮特徵的圖形」。如果有效運用這類人工智慧,就不必像現在人工作業繪製一個個動畫人物,只要用生成對抗網路一次生成多個人物,然後「挑選」出來。
比方說,使用能生成無數個人物的特徵,在電玩遊戲中針對每個玩家有不同的客製化人物。事實上,經營線上電玩遊戲的Aeria便投資了DataGrid,共同推動以人工智慧生成人物影像的專案。目前除了規畫提供利用這項技術的電玩遊戲,未來還預計發展出讓人工智慧辨識玩家喜好並配合生成遊戲人物。
不只生成影像,還能應用於加工。「把照片變成梵谷名畫」之類廣受歡迎的手機應用程式,很容易建立影像濾鏡功能,根據某些特徵來改變圖像。除此之外,要提高畫質粗劣的影像的解析度,「超解析」(super-resolution)、「降噪」之類影像處理也能有效使用生成對抗網路,目前仍持續研究開發。超解析必須生成原本非以數據存在的畫素資訊,但這種「擬真創作補足」正是生成對抗網路最擅長的領域,「成功實現了比以往超解析更漂亮的超解析影像。」(岡田)降噪方面的成果同樣效果顯著,未來可望應用在影像和照片的數位修復作業或博物館。
第三個解決方案是「學習用資料的自動生成」。想在業務上運用人工智慧,想用深度學習打造模型,雖然有這樣的期望,卻礙於收集不到學習用的資料或數量太少,這些情況尋常可見。例如偵測異常的人工智慧,即使有大量正常的影像,通常顯示異常的影像很少。這時可以運用生成對抗網路,生成各種「具備異常特徵的影像」,以這種方式來增加學習用的資料。
「如果能把一百筆資料增加到一萬筆的各種變化,深度學習的準確率大幅提高。工廠內的異常影像、產品品管檢查時發現缺失的影像、行車紀錄器拍到汽車前方有人或動物衝出來的影像等,這些希望借助運用人工智慧的異常影像數量都很少。若以生成對抗網路生成的資料來補充,將有助於建立準確率高的人工智慧模型。」(岡田)
藉由DataGrid研發的人工智慧,能夠以各種形式「無中生有」。DataGrid和面對課題的夥伴企業共同運用這些功能。岡田表示,「到頭來,人工智慧單打獨鬥什麼事都做不了,重要的是『人工智慧×未知的X』。然而,要靠自己來打造X,工程太浩大。因此,我們希望與已經擁有X的其他公司合作,繼續推動創意人工智慧的實用化。」他非常看好創意人工智慧的未來。
作者資料
日經xTREND(日経クロストレンド)
新興市場創業人的數位策略媒體。針對正在開發企業新業務、致力行銷相關業務者,每天提供包括行銷、消費、技術、資料、創新、中國、美國、技能提升等領域的最新相關實務資訊。 https://xtrend.nikkei.com/ 相關著作:《深度學習的商戰必修課:人工智慧實用案例解析,看35家走在時代尖端的日本企業如何翻轉思考活用AI》
基本資料
作者:日經xTREND(日経クロストレンド)
譯者:葉韋利(Lica Yeh)
其他:日本深度學習協會/監修(日本ディープラーニング協会)
出版社:臉譜
書系:科普漫遊2
出版日期:2020-01-30
ISBN:9789862357927
城邦書號:FQ2014
規格:平裝 / 單色 / 336頁 / 14.8cm×21cm















注意事項
- 若有任何購書問題,請參考 FAQ